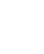Powered by
Powered by
BLOG
 最終更新日:
最終更新日:

.webp)
目次 ➖
近年、多くの企業でデータ活用が進む中、AI予測モデルを活用した意思決定が注目されています。AI予測モデルとは、過去のデータをもとにAIや機械学習を用いて将来の数値や出来事を予測する仕組みです。売上や需要の予測、顧客行動の分析、不良品の検知など、さまざまな分野で活用が広がっています。
しかし、「AI予測モデルとは具体的にどのようなものなのか」「どのように作るのか」「どのような種類やアルゴリズムがあるのか」と疑問に思う方も多いのではないでしょうか。
本記事では、AI予測モデルの基本的な仕組みから種類、代表的なアルゴリズム、作り方、評価指標、活用事例までをわかりやすく解説します。AI予測モデルの基礎知識を理解し、データ活用や業務改善に役立てたい方はぜひ参考にしてください。
AI需要予測を活用してみませんか?
サポート体制も整っているため、安心して運用できます
→資料を見てみる
AI予測モデルとは、過去のデータをもとにAI(人工知能)や機械学習を用いて将来の数値や出来事を予測する仕組みのことです。売上や需要、顧客行動などのデータを分析し、将来どのような結果になるかを数値や確率として導き出します。
近年、企業ではデータ活用が進み、販売計画や在庫管理、マーケティングなどさまざまな業務でAI予測モデルが活用されています。従来の経験や勘に頼った意思決定ではなく、データに基づいた客観的な判断ができる点が大きな特徴です。
AI予測モデルは、データのパターンや傾向を学習することで、未知のデータに対しても予測を行えるようになります。そのため、需要予測や売上予測、設備故障の予測など、将来を見据えた意思決定を支援する技術として注目されています。
ここでは、AI予測モデルの基本的な考え方として、以下のポイントを解説します。
それぞれ順番に見ていきましょう。
AI予測モデルとは、過去のデータからパターンや関係性を学習し、将来の数値や出来事を予測するAIの仕組みです。売上や需要、顧客行動、設備故障などのデータを分析し、「将来どのような結果になるか」を数値や確率として導き出します。
例えば、小売業では過去の販売データをもとに商品の需要を予測したり、製造業では設備のセンサーデータをもとに故障の発生を予測したりすることが可能です。このようにAI予測モデルは、過去のデータから規則性を学習し、それをもとに未来を予測するという特徴があります。
従来の統計分析でも予測は行われていましたが、AI予測モデルは大量のデータや複雑な関係性を扱える点が強みです。そのため近年では、マーケティング、物流、金融、製造など幅広い分野で活用が進んでいます。
予測モデルについて詳しく知りたい方はこちらの記事をご覧ください。
予測モデルの基本的な仕組みや種類、機械学習との関係性、主要なアルゴリズム、実際の活用事例、導入時の注意点がよくわかる内容になっています。
予測モデルとは?機械学習の基本から手法・ツール・活用事例まで徹底解説
AI予測モデルの多くは、機械学習(Machine Learning)の技術を基盤として構築されます。
機械学習とは、コンピュータがデータから自動的にパターンを学習し、その結果をもとに予測や判断を行う技術です。AI予測モデルは、この機械学習のアルゴリズムを利用して作られます。
例えば、以下のようなアルゴリズムがAI予測モデルに利用されます。
これらのアルゴリズムは、データの特徴やパターンを学習し、未知のデータに対して予測を行う役割を担います。つまり、機械学習はAI予測モデルを実現するための中核技術といえます。
なお、AIという言葉は広い概念ですが、その中でも「データから学習して予測を行う仕組み」がAI予測モデルです。
AI予測モデルを活用することで、企業はさまざまな予測を自動化し、意思決定を高度化できます。代表的な活用例としては、以下のようなものがあります。
1. 需要予測
過去の販売データや季節要因などをもとに、将来の販売数量や需要を予測できます。これにより、在庫の最適化や欠品防止が可能になります。
需要予測について詳しく知りたい方はこちらの記事をご覧ください。
需要予測の基本的な概念から、直面する課題とその解決策、そして精度を高めるためのポイントや最新技術の動向がよくわかる内容になっています。
需要予測とは?その意義から手法、最新の活用事例まで徹底解説
2. 売上予測
店舗や商品、地域などのデータを分析し、将来の売上を予測できます。販売計画の策定や経営判断に活用されます。
売上予測について詳しく知りたい方はこちらの記事をご覧ください。
売上予測の基本概念から、計算方法の選び方、精度を高める具体的な方法がよくわかる内容になっています。
売上予測とは?計算方法や予測の立て方、精度を高める方法を解説
3. 顧客行動の予測
顧客の購買履歴や行動データを分析し、将来の購買確率や解約リスクなどを予測できます。マーケティング施策の精度向上に役立ちます。
4. 異常や不具合の予測
設備データや品質データを分析し、故障や不良品の発生を予測できます。製造業では予知保全や品質管理に活用されています。
このようにAI予測モデルは「将来を予測することで意思決定を支援する技術」として、さまざまな業務で活用が広がっています。特にデータ量が増える現代においては、AI予測モデルの重要性はますます高まっています。
AI予測について詳しく知りたい方はこちらの記事をご覧ください。
AI予測の基本的な仕組みやメリット・デメリット、そして具体的な活用事例がよくわかる内容になっています。
AI予測とは?なぜ必要?知っておきたい仕組みや導入のメリットまで解説

AI予測モデルは、「過去のデータから関係性を学習し、そのパターンをもとに将来を予測する仕組み」で動いています。基本的には、予測したい対象(目的変数)と、それに影響を与える要因(説明変数)の関係をデータから学習し、その関係性をモデルとして構築します。
例えば、商品の販売数を予測する場合、「販売数」を予測対象とし、価格、季節、キャンペーン、天候などの要因をもとに分析します。AIはこれらのデータの組み合わせを学習することで、「どの要因がどの程度予測に影響するのか」を理解し、将来の数値を算出します。
このようなAI予測モデルの仕組みを理解するためには、次の3つの要素を押さえておくことが重要です。
これらの要素が組み合わさることで、AI予測モデルはデータから規則性を学習し、将来の予測を行えるようになります。ここからは、それぞれの要素について詳しく解説します。
目的変数とは、AI予測モデルで予測したい対象となるデータのことです。英語では「Target」や「Label」と呼ばれることもあります。
例えば、以下のようなものが目的変数になります。
このように、AI予測モデルは「どのデータを予測したいのか」を最初に決めることが重要です。目的変数の設定によって、使用するアルゴリズムやモデルの種類も変わります。
例えば、売上や販売数のような数値を予測する場合は「回帰モデル」、顧客が解約するかどうかのようにカテゴリを予測する場合は「分類モデル」が使われます。
そのため、AI予測モデルを構築する際は、まず「何を予測したいのか」という目的変数を明確にすることが重要です。
説明変数とは、目的変数に影響を与える要因となるデータのことです。英語では「Feature」と呼ばれます。
例えば、販売数量を予測する場合、次のようなデータが説明変数になります。
AI予測モデルは、これらの説明変数と目的変数の関係性を学習することで、将来の予測を行います。例えば、「気温が高いとアイスクリームの売上が増える」「セール期間中は販売数量が増える」といった関係性をデータから学習します。
なお、AI予測モデルの精度は、どの説明変数を使うかによって大きく左右されます。 そのため、予測精度を高めるためには、適切な説明変数を選定することが重要です。
AI予測モデルでは、データを大きく 「学習データ」と「予測データ」 の2種類に分けて扱います。
学習データとは、AIがデータのパターンや関係性を学習するために使用する過去のデータです。例えば、過去数年間の売上データや販売データを使ってモデルを作ります。
一方、予測データとは、作成したAI予測モデルを使って将来を予測するためのデータです。例えば、来月のキャンペーン情報や価格設定などを入力すると、AIが売上や需要を予測します。
一般的には、以下のような流れで予測が行われます。
1. 過去データを使ってAI予測モデルを学習させる
2. モデルがデータの関係性を理解する
3. 新しいデータを入力する
4. 将来の数値や結果を予測する
このように、AI予測モデルは「過去データで学習し、未来を予測する」という仕組みで動いています。

AI予測モデルにはさまざまな種類がありますが、予測する対象やデータの性質によって大きく 「回帰モデル」「分類モデル」「時系列予測モデル」 の3つに分けることができます。
それぞれのモデルは、予測したいデータの種類(数値なのか、カテゴリなのか、時間変化を伴うのか)によって使い分けられます。 適切なモデルを選択することは、AI予測モデルの精度を高めるうえで非常に重要です。
ここでは、AI予測モデルの代表的な3つの種類について解説します。
回帰モデルとは、数値データを予測するAI予測モデルのことです。将来の売上や需要、価格など、連続した数値を予測する場合に利用されます。
例えば、以下のような予測に回帰モデルが使われます。
回帰モデルでは、説明変数(価格、季節、広告など)と目的変数(売上や販売数)の関係性を学習し、将来の数値を算出します。代表的なアルゴリズムとしては、線形回帰、ランダムフォレスト、勾配ブースティングなどがあります。
企業のデータ分析では、売上や需要といった数値を予測するケースが多いため、回帰モデルはAI予測モデルの中でも特に活用されることが多い手法です。
分類モデルとは、データを特定のカテゴリに分類するAI予測モデルです。予測結果は数値ではなく、「はい/いいえ」や「A・B・C」といったカテゴリになります。
例えば、以下のような予測に分類モデルが使われます。
分類モデルでは、過去のデータをもとに「どの特徴を持つデータがどのカテゴリに属するのか」を学習します。代表的なアルゴリズムとしては、決定木、ロジスティック回帰、ランダムフォレスト、XGBoostなどがあります。
マーケティングや品質管理などの分野では、顧客行動の予測や異常検知などに分類モデルが広く活用されています。
時系列予測モデルとは、時間の流れに沿って変化するデータを予測するAI予測モデルです。売上や需要、アクセス数など、時間とともに変化するデータの予測に適しています。
例えば、次のような予測に活用されます。
時系列データには、季節変動やトレンドなどの特徴があります。例えば、夏はアイスが売れやすい、年末は売上が増えるといったパターンです。時系列予測モデルは、こうした時間による変化や周期性を考慮して将来を予測する点が特徴です。
代表的な手法には、ARIMA、Prophet、LSTM(ディープラーニング)などがあります。
特に小売業や製造業では、在庫最適化や生産計画に関わる需要予測で時系列予測モデルが重要な役割を果たしています。
AI予測モデルは、データの関係性やパターンを学習する「アルゴリズム」によって構築されます。アルゴリズムとは、データから規則性を見つけ出し、予測を行うための計算手法のことです。
現在のAI予測モデルでは、統計モデルから機械学習、ディープラーニングまでさまざまなアルゴリズムが利用されています。予測したいデータの種類やデータ量、目的によって適切なアルゴリズムを選択することが重要です。
ここでは、AI予測モデルでよく使われる代表的なアルゴリズムを紹介します。
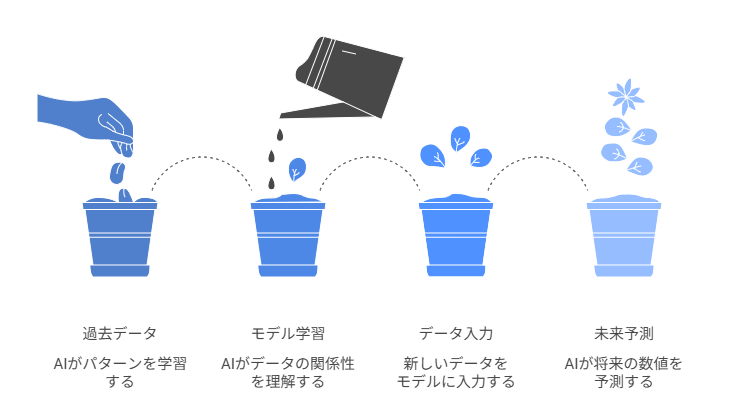
線形回帰(Linear Regression)は、最も基本的なAI予測モデルのアルゴリズムの一つです。説明変数と目的変数の関係を「直線」で表現し、数値を予測します。
例えば、次のような関係を分析する際に利用されます。
線形回帰はモデルの仕組みが比較的シンプルで、どの要因がどの程度結果に影響しているかを理解しやすいという特徴があります。そのため、データ分析の初期段階やベースラインモデルとしてよく使用されます。
決定木(Decision Tree)は、データを条件分岐によって分類・予測するアルゴリズムです。木の構造のようにデータを分岐させながら、最終的な予測結果を導き出します。
例えば、次のような条件分岐で予測が行われます。
決定木は、モデルの構造が可視化しやすく、結果を理解しやすいというメリットがあります。一方で、単体では過学習(学習データに過度に適合する現象)が起こりやすいという特徴もあります。
ランダムフォレスト(Random Forest)は、複数の決定木を組み合わせて予測を行うアルゴリズムです。多数の決定木の結果を統合することで、より安定した予測が可能になります。
この手法では、異なるデータや特徴量を使って多数の決定木を作成し、それぞれの予測結果を平均または多数決で統合します。これにより、単一の決定木よりも予測精度や汎用性が高いモデルを構築できるのが特徴です。
ランダムフォレストは、分類問題と回帰問題の両方に対応できるため、さまざまなデータ分析で利用されています。
勾配ブースティング(Gradient Boosting)は、複数の弱いモデルを順番に学習させて精度を高めるアルゴリズムです。前のモデルの誤差を補うように次のモデルを学習させることで、より精度の高い予測が可能になります。
特に実務でよく利用される実装として、以下のようなものがあります。
これらは大量のデータを高速に処理できるため、データ分析コンペティションや実務のAI予測モデルで非常に多く利用されているアルゴリズムです。売上予測や需要予測、顧客行動分析など、さまざまな分野で活用されています。
ディープラーニング(Deep Learning)は、多層のニューラルネットワークを用いた高度なAIアルゴリズムです。人間の脳の神経回路を模した構造を持ち、複雑なパターンを学習できるのが特徴です。
ディープラーニングは、以下のような分野で特に活用されています。
近年では、需要予測や売上予測などの分野でも、LSTMやTransformerといったディープラーニングモデルが活用されるケースが増えています。
ただし、ディープラーニングは大量のデータや計算リソースが必要になる場合が多いため、用途やデータ量に応じて適切なアルゴリズムを選択することが重要です。
需要予測のアルゴリズムについて詳しく知りたい方はこちらの記事をご覧ください。
AIを活用した需要予測の仕組みやアルゴリズム、導入によって得られるメリットがよくわかる内容になっています。
需要予測のアルゴリズムとは?導入事例・仕組み・メリットも解説

AI予測モデルは、単にアルゴリズムを選んで作るだけではなく、課題設定からデータ準備、モデル構築、運用までの一連のプロセスを通じて構築されます。特にビジネスで活用する場合は、予測精度だけでなく、実際の業務で使える形にすることが重要です。
一般的にAI予測モデルの構築は、次のような流れで進められます。
それぞれのステップについて詳しく解説します。
AI予測モデルを作る最初のステップは、どのような課題を解決したいのかを明確にすることです。予測モデルは目的が曖昧なまま作っても、実際の業務で活用できないケースが多くあります。
例えば、次のようなユースケースがあります。
このように、AI予測モデルでは「何を予測するのか(目的変数)」を明確にすることが重要です。目的が明確になることで、必要なデータや適切なアルゴリズムも決まりやすくなります。
次のステップは、AI予測モデルの学習に必要なデータを収集することです。AIの予測精度は、データの量と質に大きく依存します。
例えば、需要予測の場合には以下のようなデータが利用されます。
これらのデータを収集し、予測に必要な情報を揃えることで、AI予測モデルの精度を高めることができます。
収集したデータは、そのままではAI予測モデルに利用できないことが多いため、データ前処理(データクレンジング)を行います。
主な前処理には以下のようなものがあります。
この工程はAI予測モデルの精度に大きく影響する重要なプロセスであり、実務では多くの時間が費やされることもあります。
データの準備が整ったら、機械学習アルゴリズムを用いてAI予測モデルを構築します。
ここでは、次のようなアルゴリズムが利用されることがあります。
アルゴリズムの選択やパラメータ調整(ハイパーパラメータチューニング)を行いながら、最適なAI予測モデルを作成していきます。
モデルを作成した後は、予測精度を評価する工程が必要です。学習データとは別のデータを使い、AI予測モデルがどれくらい正確に予測できるかを確認します。
代表的な評価指標には次のようなものがあります。
これらの指標をもとに、モデルの改善やアルゴリズムの変更を行い、より精度の高いAI予測モデルを作ります。
AI予測モデルは、作って終わりではありません。実際の業務で運用しながら継続的に改善していくことが重要です。
例えば、以下のような対応が必要になります。
市場環境や顧客行動は時間とともに変化するため、AI予測モデルも定期的に再学習させることで精度を維持する必要があります。

AI予測モデルを構築した後は、どの程度正確に予測できているのかを評価することが重要です。モデルの精度を客観的に判断するために、さまざまな評価指標が利用されます。
評価指標は、予測するデータの種類(数値予測か分類予測か)によって使い分ける必要があります。例えば、売上や需要のような数値予測では誤差を測る指標が使われ、顧客の解約有無のような分類問題では正解率などの指標が使われます。
ここでは、AI予測モデルでよく利用される代表的な評価指標を紹介します。
RMSE(Root Mean Squared Error:平均平方二乗誤差)は、予測値と実際の値の誤差の大きさを測る代表的な指標です。予測値と実測値の差を二乗し、その平均の平方根を取ることで算出されます。
RMSEは、誤差が大きいほど値が大きくなるため、数値が小さいほど精度の高いAI予測モデルであると判断できます。また、大きな誤差を強く評価する特徴があるため、外れ値の影響を受けやすいという性質もあります。
売上予測や需要予測など、数値を予測する回帰モデルの評価に広く利用されています。
MAE(Mean Absolute Error:平均絶対誤差)は、予測値と実際の値の差の絶対値の平均を計算する評価指標です。RMSEと同様に、回帰モデルの評価でよく使用されます。
MAEは、誤差の絶対値をそのまま平均するため、直感的に「平均してどれくらいの誤差があるか」を理解しやすいという特徴があります。また、RMSEと比較すると外れ値の影響を受けにくい指標です。
そのため、実務ではRMSEとMAEの両方を確認しながら、AI予測モデルの精度を評価するケースが多くあります。
R²(決定係数)は、AI予測モデルがデータのばらつきをどれだけ説明できているかを示す指標です。値は一般的に0〜1の範囲で表され、1に近いほどモデルの説明力が高いと判断されます。
例えば、R²が0.8の場合、データの変動の約80%をモデルが説明できていることを意味します。回帰モデルの評価では、RMSEやMAEとあわせて確認されることが多い指標です。
ただし、R²が高いからといって必ずしも予測精度が高いとは限らないため、複数の評価指標を組み合わせてAI予測モデルを評価することが重要です。
Accuracy(正解率)とF1スコアは、分類モデルの評価に使われる指標です。
Accuracyは、全体のデータのうちどれだけ正しく分類できたかを示すシンプルな指標です。例えば、100件中90件を正しく分類できた場合、Accuracyは90%になります。
一方、F1スコアは適合率(Precision)と再現率(Recall)のバランスを評価する指標です。特に、データの偏りがある場合や、不良品検知・不正検知などの重要な分類問題ではF1スコアが重視されます。
このように、AI予測モデルでは目的に応じて適切な評価指標を選び、モデルの性能を客観的に判断することが重要です。

AI予測モデルは、さまざまな業界や業務で活用されています。過去のデータから将来の結果を予測できるため、意思決定の高度化や業務効率化につながる点が大きなメリットです。
特に企業では、売上や需要、品質管理、マーケティングなどの分野でAI予測モデルの活用が進んでいます。ここでは代表的な活用事例を紹介します。
需要予測は、AI予測モデルの代表的な活用分野の一つです。過去の販売データや季節要因、キャンペーン情報などをもとに、将来の販売数量や需要を予測します。
例えば、小売業では次のようなデータを使って需要予測が行われます。
AI予測モデルを活用することで、在庫の最適化や欠品防止、過剰在庫の削減につながります。これにより、在庫コストの削減や販売機会の最大化が期待できます。
AI予測モデルは、将来の売上を予測するためにも活用されています。例えば、新規店舗の出店計画や事業計画の策定などで利用されるケースが多くあります。
売上予測では、以下のようなデータが活用されます。
これらのデータをAI予測モデルで分析することで、新店舗の売上見込みや将来の売上推移を予測することが可能になります。経営判断や投資判断を行う際にも重要な情報となります。
製造業では、AI予測モデルを使って不良品の発生を予測する取り組みも進んでいます。設備データや品質データを分析することで、不良品が発生する可能性を事前に予測できます。
例えば、以下のようなデータが利用されます。
AI予測モデルによって不良品の発生を予測できれば、製造条件の調整や設備メンテナンスを事前に行うことが可能になります。これにより品質向上やコスト削減につながります。
AI予測モデルは、顧客の行動を予測するマーケティング分野でも活用されています。顧客の購買履歴や行動データを分析することで、将来の行動を予測できます。
例えば、次のような予測が可能です。
これにより、ターゲットを絞ったマーケティング施策や顧客維持施策を実施できるようになります。結果として、顧客満足度の向上や売上拡大につながります。

AI予測モデルを導入することで、企業はデータを活用した高度な意思決定が可能になります。従来は経験や勘に依存していた判断も、データとAIによる客観的な分析に基づいて行えるようになるため、業務の精度や効率を大きく向上させることができます。
また、AI予測モデルは一度構築すれば継続的にデータを分析し続けられるため、業務の自動化やデータ活用の高度化にもつながる点が大きなメリットです。ここでは、AI予測モデル導入の代表的なメリットを解説します。
AI予測モデルを導入することで、データに基づいた意思決定が可能になります。
従来のビジネスでは、経験や勘に頼って判断するケースも少なくありませんでした。しかしAI予測モデルを活用することで、過去データを分析し、将来の結果を予測したうえで意思決定を行うことができます。
例えば、次のような意思決定の高度化が期待できます。
このように、AI予測モデルはデータドリブン経営を実現する重要な基盤となります。
AI予測モデルを導入すると、これまで人手で行っていた分析業務を自動化できるようになります。
例えば、従来は担当者がExcelなどを使って行っていた売上予測や需要予測も、AI予測モデルを利用すれば定期的に自動で予測結果を算出することが可能です。
これにより、次のような効果が期待できます。
結果として、担当者はデータ分析そのものではなく、予測結果をもとにした戦略立案や意思決定に集中できるようになります。
AI予測モデルの導入は、企業のデータ活用レベルを大きく向上させる効果もあります。
多くの企業では、販売データや顧客データ、設備データなど大量のデータが蓄積されています。しかし、それらのデータを十分に活用できていないケースも少なくありません。
AI予測モデルを活用することで、これらのデータを分析し、次のような価値を生み出すことができます。
このように、AI予測モデルは企業のデータを「価値ある情報」に変換する重要な技術といえます。

AI予測モデルは多くのメリットをもたらしますが、導入すればすぐに成果が出るとは限りません。データやモデル、運用体制など複数の要素が関わるため、導入時にはいくつかの課題が存在します。
特に企業でAI予測モデルを活用する場合は、技術面だけでなく、データ管理や業務運用の観点も含めて検討することが重要です。ここでは、AI予測モデル導入時に多くの企業が直面する代表的な課題を紹介します。
AI予測モデルの精度は、使用するデータの品質に大きく依存します。
そのため、データの欠損や誤り、ばらつきが多い場合、予測精度が十分に出ないことがあります。
例えば、以下のような問題が発生することがあります。
このような問題がある場合、データの整理や前処理(データクレンジング)を行う必要があります。AI予測モデルの構築では、このデータ整備の工程が非常に重要であり、実務では多くの時間を要することもあります。
AI予測モデルを導入する際には、期待した精度が出ないケースがあることも課題の一つです。
その理由として、次のような要因が考えられます。
AI予測モデルは一度作って終わりではなく、評価と改善を繰り返しながら精度を高めていくことが重要です。そのため、モデル改善のプロセスを継続的に行う体制を整えることが求められます。
AI予測モデルは構築した後も、継続的な運用やメンテナンスが必要です。
ビジネス環境や市場の状況は時間とともに変化するため、モデルの精度も徐々に低下することがあります。この現象は「モデルドリフト」と呼ばれることもあります。
そのため、AI予測モデルを実務で活用する場合は、以下のような運用が必要になります。
このように、AI予測モデルは継続的に改善・運用していく仕組みを整えることが重要です。

Deep Predictorは、東証グロース市場に上場しているAI CROSS株式会社(証券コード:4476)が提供するAI需要予測ツールです。売上や販売数、出荷量といった需要をAIで予測し、その結果に基づいて適切な発注量を算出することも可能です。余剰在庫の削減・欠品防止・生産計画の改善など、現場の課題解決に直結します。
特に大きな特徴は、「現場担当者が自ら自走できる」ことをコンセプトに設計されている点です。複雑な設定や専門知識を必要とせず、店舗・事業部・現場の担当者が自らデータを分析し、AIによる予測結果を日々の意思決定に活用できます。これにより、これまで専門部署に依存していた分析業務を分散し、現場主導のスピード感ある改善サイクルを実現します。
また、導入後は活用方法の設計や運用定着まで伴走するサポート体制を整えているため、初めてAI予測に取り組む企業でも安心して利用を開始できます。ノーコードで高度な予測精度と運用性を両立したDeep Predictorは、これからAI予測に取り組みたい企業にとって心強い選択肢です。
さらに、予測結果を日々の意思決定に活用できるため、本記事で扱ったように、需要予測を活用し在庫問題や発注問題の改善にも効果を発揮します。
AI需要予測を活用してみませんか?
サポート体制も整っているため、安心して運用できます
→資料を見てみる

AI予測モデルとは、過去のデータをもとにAIや機械学習を用いて将来の数値や出来事を予測する仕組みです。売上や需要、顧客行動などのデータを分析することで、企業の意思決定をデータに基づいて行えるようになります。
AI予測モデルは、目的変数と説明変数の関係性を学習することで予測を行います。また、回帰モデルや分類モデル、時系列予測モデルなど、予測したいデータの種類に応じてさまざまなモデルが利用される点も特徴です。
さらに、AI予測モデルの構築は以下のようなプロセスで進められます。
このようなステップを通じて、AI予測モデルを実際の業務に活用できる形にしていきます。
AI予測モデルを導入することで、データに基づいた意思決定の高度化、業務の自動化、データ活用の促進といったメリットが期待できます。一方で、データ品質の確保やモデル精度の改善、継続的な運用などの課題にも対応する必要があります。
近年では、多くの企業がデータ活用を進めており、AI予測モデルはその中核となる技術として注目されています。自社の業務課題に適した形でAI予測モデルを活用することで、より高度なデータドリブン経営の実現につながるでしょう。
また、専門的な知識や開発リソースが不足している場合には、Deep PredictorのようなAI予測サービスを活用することも有効な選択肢です。効率的に予測モデルを導入・運用する手段として、こうしたサービスの活用もぜひ検討してみてください。
AI予測モデルとは、過去のデータをもとにAIや機械学習を用いて将来の数値や出来事を予測する仕組みです。売上や需要、顧客行動などのデータを分析し、将来どのような結果になるかを予測します。
近年では、小売業の需要予測、製造業の品質予測、マーケティングの顧客行動予測など、さまざまな分野でAI予測モデルが活用されています。
AI予測モデルは、一般的に次のような手順で作成されます。
1. 課題・ユースケースの整理
2. データ収集
3. データ前処理
4. モデル構築(機械学習アルゴリズムの適用)
5. 精度評価
6. 運用・再学習
このように、データの準備からモデルの運用までのプロセスを通じてAI予測モデルを構築します。
AI予測モデルは、予測するデータの種類によって主に次の3つに分類されます。
用途やデータの特性に応じて、適切なモデルを選択することが重要です。
AI予測モデルの精度は、評価指標を用いて客観的に評価します。代表的な指標には以下があります。
回帰モデル(数値予測)
分類モデル(カテゴリ予測)
これらの指標を組み合わせて評価することで、AI予測モデルの性能を適切に判断できます。
近年では、ノーコードやローコードでAI予測モデルを作成できるツールも増えており、専門的なプログラミング知識がなくてもモデルを構築できるケースがあります。
ただし、予測精度を高めるためには、データ分析や機械学習の基本的な知識があるとより効果的です。また、実務でAI予測モデルを活用する場合は、データ整備や運用体制の構築も重要になります。